
Tesla Locking Sounds
5 octobre 2022
Bien préparer sa prise de son
12 décembre 2022Effectuer une bonne prise de son ne consiste pas uniquement au choix d’un microphone approprié et au bon placement et orientation de celui-ci. Il s’agit aussi de choisir les paramètres optimaux sur son enregistreur pour obtenir le meilleur résultat possible. Voici les divers éléments à prendre en compte lors de toute prise de son.
Avant de démarrer cet article, et si l’envie vous vient d’aller plus loin dans votre quête de l’enregistrement parfait, je donne une formation sur la prise de son en présentiel. N’hésitez pas à me contacter pour discuter de cela!
Format
Tous les enregistreurs permettent d’enregistrer en wav et en mp3. Privilégier le format wav non compressé pour bénéficier d’une qualité maximale. Rien ne vous empêche de compresser le fichier en mp3 par la suite si besoin. Mais le contraire sera impossible, car si l’enregistrement se fait en mp3, les données compressées directement à l’écriture ne pourront être récupérées. Nous avons la chance en audio d’avoir des fichiers relativement légers en comparaison des fichiers vidéos. Optez donc pour une grosse carte mémoire et ne lésinez pas sur la qualité des fichiers (64Go voire 128Go).
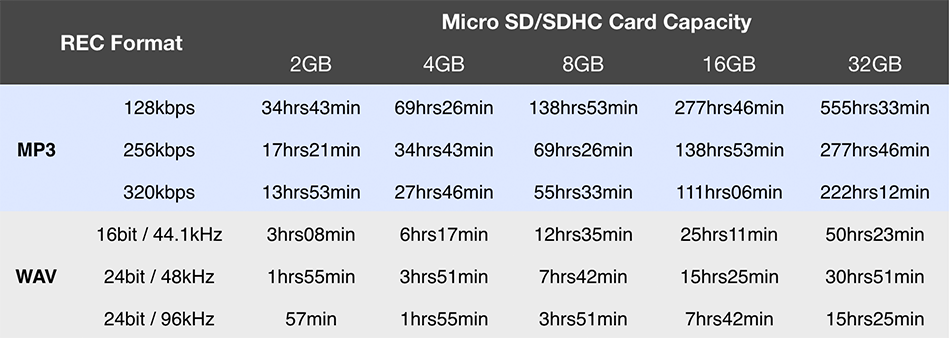
Tableau représentant la taille d’un fichier en fonction de son format et de sa qualité (fichier stéréo)
Mono/Poly
Les enregistreurs multipistes donnent accès à plusieurs options lors de l’écriture des fichiers. Il existe souvent les modes poly ou mono.
Le premier mode, poly, enregistre ainsi toutes les sources en un fichier unique. Ainsi, si ce sont 8 sources qui sont branchées simultanément sur votre enregistreur, ce sera un fichier d’autant de pistes qui sera créé. Pour un enregistrement de musique en multipiste, cela pourra être très pratique pour conserver la synchronisation parfaite de tous les fichiers (rarement destinée à être découpés par la suite).
Le seconde mode, mono, enregistre chacune des pistes dans des fichiers séparés. Cette option est très pratique lorsque l’on opère à l’enregistrement d’une émission TV regroupant plusieurs intervenants via divers micros (généralement des micros-cravates). Opérer de la sorte permettra ainsi au montage de faire des découpes de fichiers avec plus de facilité (on coupe généralement le micro de l’invité qui ne parle pas pour éviter des bruits de fond trop importants), sans devoir s’amuser à replacer la balance gauche-droite des fichiers. En effet, si l’on enregistre 2 pistes indépendantes dans un enregistreur 2 pistes sans passer par le mode mono, l’enregistreur créera alors un fichier « stéréo » avec à gauche la piste 1 et à droite la piste 2. Cela obligera donc lors du montage à devoir replacer la balance de chacun des fichiers sur une piste mono centrale. Vous pouvez donc éviter cette étape dès l’enregistrement.
Certains enregistreurs possèdent plusieurs systèmes de sauvegarde des fichiers (en Compact Flash, Carte SD, disque interne, etc.) il est parfois possible de choisir les 2 options à la fois. C’est le cas notamment avec les Zoom F4, Zoom F8, ou la série 8 de Sound Devices possédant 2 fentes pour cartes SD. Il est ainsi possible de leur demander d’enregistrer par exemple en mode mono sur la carte SD 1 et en mode poly sur la carte SD 2.
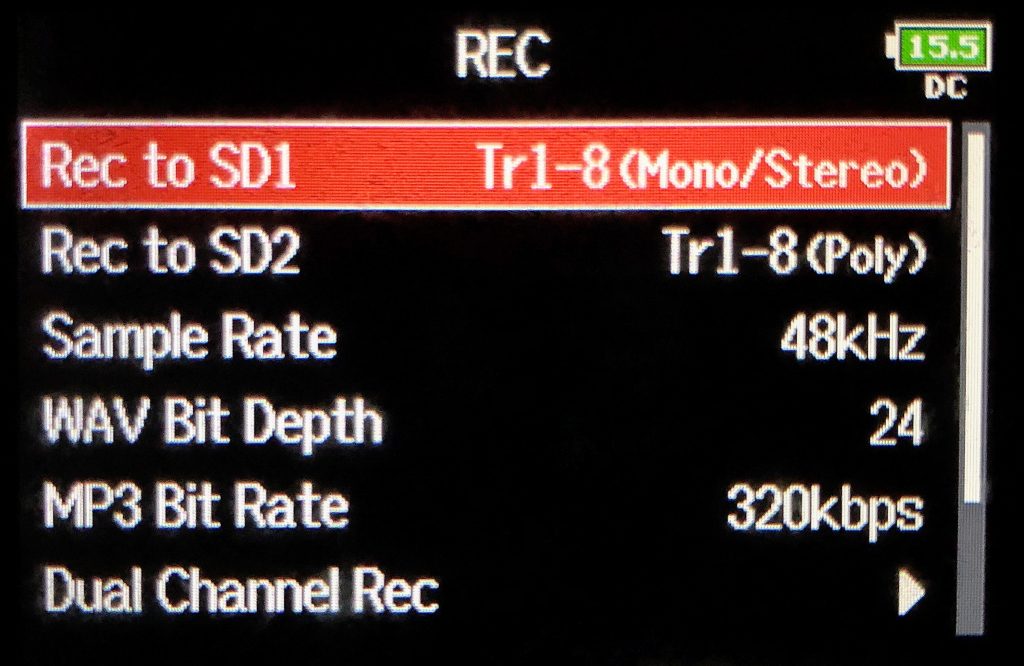
Le menu « Rec » du Zoom F8
Pour finir, je ne saurais que trop vous recommander de ne pas enclencher les pistes que vous n’utilisez pas, sous peine d’alourdir la taille de vos fichiers et de votre session de montage inutilement. En effet, une piste enregistrée, même si aucun son ne transite par elle (en silencieux) pèsera tout autant qu’une piste contenant du son.
Dual Channel Rec
Certains enregistreurs permettent d’effectuer un double enregistrement. Voici un exemple de situation. On s’apprête à enregistrer une voix ou un bruitage mais on ne sait pas trop si le réglage du niveau va être opportun et si on ne risque pas de partir en saturation. Le Dual Channel Rec permet alors d’enregistrer une seconde copie du signal, sur une autre piste, avec un niveau différent. Le Zoom F8 propose alors les pistes 5-8 en copie des pistes 1-4. On pourrait donc imaginer que sur les pistes 1-4 on règle les potentiomètres de volumes à 3h et que sur les pistes 5-8 on les positionne sur 12h. Si la piste 2 venait ainsi à saturer, on pourrait toujours récupérer le signal de la piste 6.

Frequency (fréquence d’échantillonnage)
La fréquence d’échantillonnage détermine le nombre de fois où l’enregistreur immortalisera une partie du signal sonore pendant une seconde. En théorie, et en toute logique, plus la valeur sera élevée, plus la captation sonore sera précise, bien qu’à l’oreille, la différence ne soit pas évidente.
En vidéo, la norme audio est de 48kHz, soit une captation du signal sonore 48’000 fois par seconde. Je vous conseillerais donc de ne jamais descendre en-dessous et d’oublier la valeur de 44,1 Khz, qui correspondait à la fréquence d’échantillonnage de l’époque du CD. Privilégiez même une fréquence de 96kHz pour les enregistrements de bruitages. En effet, cela permettra d’avoir une meilleure définition sonore et surtout la possibilité de changer la tonalité d’un son (le pitcher) sans trop en altérer sa qualité. Bien-sûr enregistrer en haute qualité pèse plus lourd (2 fois plus en 96kHz qu’en 48kHz) mais avec les larges espaces de stockage que nous avons de nos jours, cela n’a plus de sens de chercher à réduire au minimum la taille de ses fichiers.
Bitrate (taux de conversion)
Le bitrate détermine le nombre de valeurs différentes possible pour coder les données de volume d’un son. Encore une fois de toute évidence, plus sa valeur est élevée, plus précise sera la reproduction. Ainsi, enregistrer en 16 bit permettra de coder 65536 valeurs différentes alors qu’un enregistrement en 24 bit permettra de coder 16 777 216 valeurs différentes, soit 256 fois plus ! Bien-sûr, cela générera des fichiers plus lourds, mais le rendu en sera meilleur, surtout sur des bruitages ou des enregistrements avec des niveaux sonores faibles. Car c’est là que le bât blesse en numérique. Ainsi, un léger crépitement serait donc susceptible d’apparaître sur les sources faibles avec un bitrate à 16bit (voire en-dessous), car l’enregistreur n’aura pas assez de valeurs différentes pour encoder de belles variations de volumes nettes. Mais l’avantage ne s’arrête pas là. En effet, alors que les 16 bit sont capables de reproduire une plage dynamique de 96dB, un encodage en 24 bit permettra lui de reproduire une dynamique de 144dB, bien plus proche de celle de l’oreille humaine, équivalant à 138dB. Encore une fois, avec un bitrate élevé, la fidélité du signal sera donc beaucoup plus proche de ce que nous entendons avec notre système auditif.
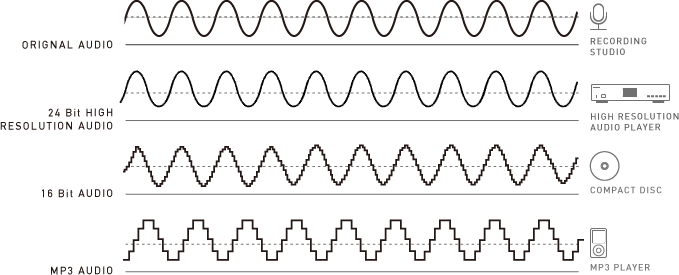
Tableau représentant la qualité d’un signal digital en fonction du choix de son bitrate
Low Cut (ou HPF)
Le low cut ou high-pass filter (également appelé coupe-bas ou passe-haut en français), détermine la quantité de fréquences graves qui sera ôtée du signal dès l’enregistrement. Tout d’abord pourquoi le faire ? Il faut savoir qu’entre les valeurs de 20Hz et 20000Hz que notre oreille est capable d’entendre, il est bien rare qu’un signal audio recouvre l’entier du spectre sonore. Il peut donc être parfois utile de couper dès la prise les fréquences inutiles qui viennent polluer celle-ci. Ainsi, lors d’un enregistrement de voix à la perche en milieu urbain par exemple, il n’est pas rare qu’un bruit de voiture, bien présent dans les basses, vienne perturber une prise. Avec un coupe-bas, celui-ci sera bien moins présent sur le signal est rendra la voix plus distincte. Cela permettra également de réduire voire d’ôter complètement les éventuels bruits de vent faible et de manipulation de perche. A vrai dire, lors d’un tournage j’ai quasiment systématiquement le low cut enclenché sur mes entrées, avec une valeur généralement de 80Hz et une pente de -24dB/octave. Que représente cette dernière valeur ? C’est la pente de coupure de la fréquence choisie. Ainsi pour une pente du premier ordre (à 6dB/oct), la pente sera douce, réduisant petit à petit le volume des fréquences inférieure à la valeur de coupure choisie. Avec une pente du 2ème ordre (12dB/oct) elle sera déjà plus pentue et ainsi de suite, jusqu’à avoir quelque chose de beaucoup plus abrupte avec une pente du 4ème ordre à -24dB/oct, comme le représente le graphique ci-dessous.
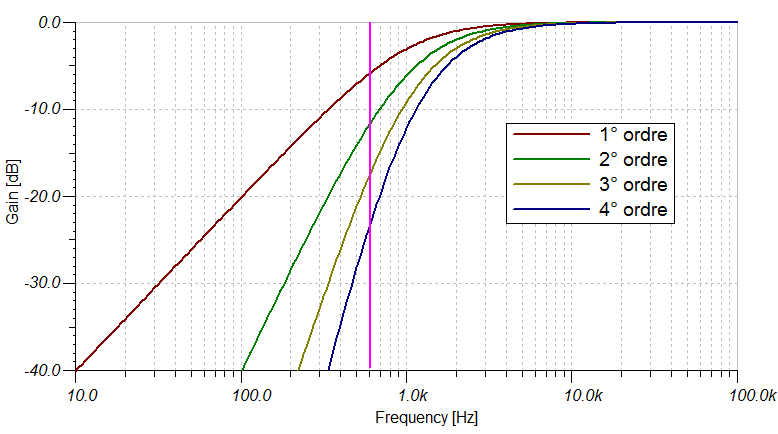 Graphique représentant les diverses courbes d’un filtre low cut (passe-bas)
Graphique représentant les diverses courbes d’un filtre low cut (passe-bas)
Phantom Power (alimentation fantôme)
Le Phantom Power, ou alimentation fantôme en français, est une source d’énergie de 48V utilisée pour alimenter un microphone en électricité. Dans quel cas l’utilise-t-on ? Avec les modèles électrostatiques (type Rode NTG3, Sennheiser MKH50 ou Schoeps CMIT pour ne citer qu’eux), car il est nécessaire de fournir de l’électricité au microphone pour alimenter le condensateur qui le compose, ainsi que l’amplificateur adaptateur d’impédance. Inutile de trop se prendre la tête avec de la physique, tout ce qu’il y a à savoir c’est que cette source d’énergie est délivrée par l’enregistreur (ou une table de mixage) et qu’il transite via le câble audio raccordé au microphone. Sans avoir enclenché l’alimentation fantôme pour un microphone qui le nécessite, vous n’aurez pas de son. Si vous n’entendez rien une fois votre microphone branché et votre potentiomètre de volume levé, c’est que vous avez certainement oublié cette étape. A noter que si un enregistreur doit alimenter un microphone en 48V, cela usera sa batterie plus rapidement. Ainsi, le Zoom H4n par exemple n’a plus que très peu d’autonomie dès lors qu’il doit alimenter un microphone.
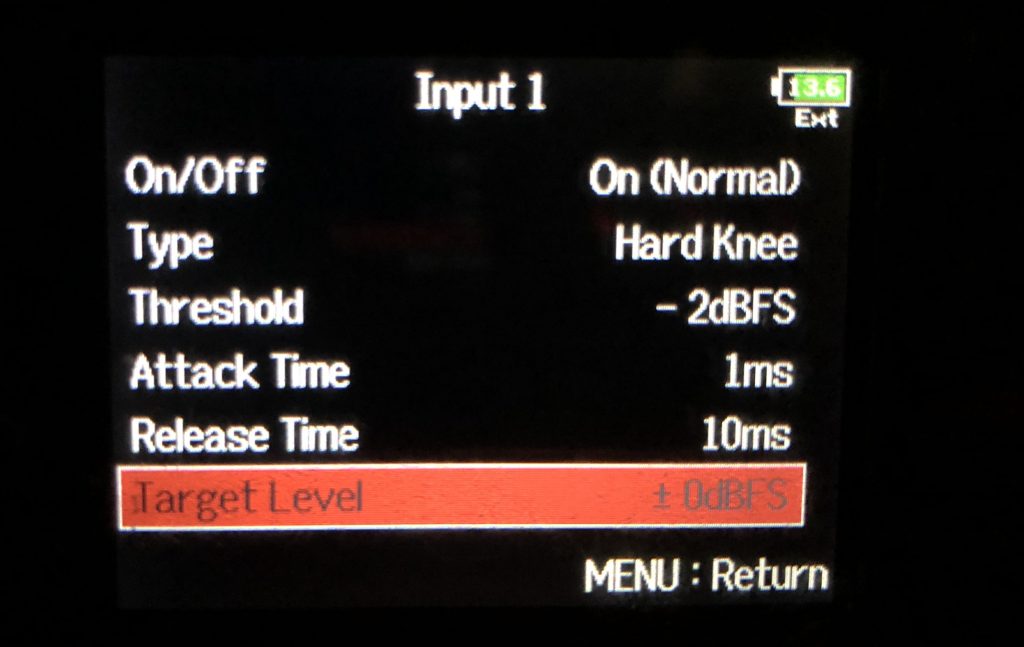
Le compresseur / limiteur
Le compresseur / limiteur permet de limiter la quantité de signal entrant dans l’enregistreur, avant qu’il ne soit immortalisé. Un signal trop fort, mais limité, ne viendra ainsi pas saturer le préamplificateur. En ce qui me concerne, je ne compresse jamais à la prise pour éviter de limiter la dynamique. Si besoin, je le ferai en post-production Par contre, j’enclenche toujours un limiteur par sécurité.
Plusieurs paramètres sont alors réglables. Les voici.
Type (Soft Knee/Hard Knee): Ce paramètre permet de choisir la pente du compresseur. Ainsi, avec un Soft Knee, le signal viendra progressivement s’atténuer avant même qu’il n’atteigne le seuil de traitement choisi pour avoir un effet plus doux, il agit donc plutôt comme un compresseur. Avec un Hard Knee, sur les crêtes qui dépassent le seuil sont atténuées. Il agit donc réellement sous forme de limiteur. Je l’utilise généralement sous Hard Knee car je ne cherche pas à compresser mon signal mais simplement à limiter les pics trop élevés.
Threshold: C’est le seuil à partir duquel le compresseur / limiteur entre en action. J’ai choisi une marge de -2dBFS pour qu’il n’intervienne qu’au moment où cela risquerait de venir saturer et pas avant. Une valeur inférieure risquerait de trop écraser le signal et de lui ôter toute dynamique.
Attack Time: C’est la durée à partir de laquelle le compresseur / limiteur agit une fois qu’il a dépassé le seuil. J’ai choisi la valeur la plus courte pour qu’il entre immédiatement en action quand une signal risquerait la saturation. J’ai choisi 1ms pour qu’il entre en action extrêmement rapidement.
Release Time: C’est la durée à partir de laquelle le compresseur / limiteur cesse d’agir une fois qu’il est repassé en-dessous de la valeur du seuil. Avoir une valeur trop petite risquerait de donner un effet de pompage trop important et une valeur trop faible aurait un résultat pas assez naturel. Le niveau reviendrait ainsi beaucoup trop lentement à sa valeur initiale et deviendrait par exemple inutilisable lors d’une interview. Potentiellement intéressant pour une application artistique, notamment sur de la musique, mais à mon avis sans grand intérêt en mode prise de son sur tournage / bruitages.
Output (sortie audio à destination de la caméra)
Lorsque l’on enregistre de l’audio en synchronisation avec de l’image, il est primordial de réfléchir à la façon dont les fichiers seront synchronisés par la suite. Car bien souvent, la vidéo et l’audio sont enregistrés sur 2 systèmes séparés, la caméra s’occupant de l’image et un enregistreur externe s’occupant du son. Il n’y a pas vraiment de caméra réputée pour la bonne qualité de ses préamplis audio, raison pour laquelle un appareil séparé est généralement utilisé pour cette tâche. De plus, le preneur de son se trouve rarement au même endroit que la caméra lors de la captation sonore (il est souvent beaucoup plus proche de la source). Cela permet donc que chaque partie soit indépendantes les unes des autres. Quoiqu’il en soit, il est nécessaire à un moment ou l’autre de resynchroniser les 2 sources pour que l’image et l’audio ne fassent plus qu’un au montage.
Il existe alors différentes méthodes. Aucune n’est vraiment plus utile, valable ou qualitative qu’une autre, c’est uniquement une question de méthodologie, de pratique et de goût. À vous de choisir celle que vous préférez et qui fonctionnera le mieux avec votre projet, le matériel utilisé ou avec le duo caméraman-preneur de son du projet.

- Le clap
La méthode antique utilisée depuis les débuts du cinéma sonore, c’est le clap. La manière de procéder est bien simple. On referme un clap d’un coup sec face à la caméra et près du micro (à vous de vous en approcher au maximum avec votre perche ou un micro-cravate à ce moment-là). Celui-ci produira un son puissant et sec, très facilement reconnaissable sur la forme d’onde audio (comme on peut l’apercevoir sur l’image ci-dessous). Au montage, il suffira simplement de recaler le son par rapport à l’image, en faisant correspondre le gros pic audio avec le moment où le clap commence à se refermer complètement. Nul besoin de posséder un véritable clap de cinéma pour effectuer cette opération, le clap pouvant tout à fait être effectué à la main, de façon visible à l’image. L’avantage de la version cinéma étant surtout la possibilité d’y annoter le nom et le numéro de la prise en cours.
Quelle que soit la méthode utilisée parmi celles que je cite, je conseillerais systématiquement de faire un clap par sécurité car il permettra toujours de potentiellement resynchroniser un signal audio qui aurait pu être perdu sur la caméra à un moment ou l’autre du tournage comme nous pourrons le voir plus loin.
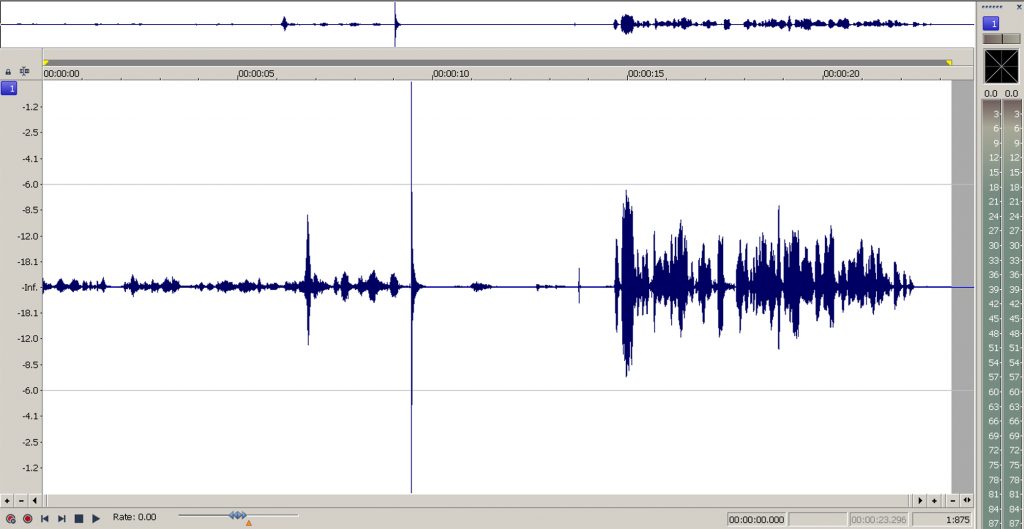
Sur cette image, on distincte très bien le pic du clap effectué juste avant la 10è seconde
- Utilisation d’un microphone de référence
L’une des autres méthodes couramment utilisées consiste à faire usage d’un microphone de référence sur la caméra. Celui-ci, qui n’a pas besoin d’être un modèle haut de gamme, enregistre la scène également conjointement au preneur de son, mais avec comme seul but de conserver une trace audio de la prise. Celle-ci permettra aux logiciels tels que Premier, Final Cut ou PluralEyes d’analyser la forme d’onde et de trouver sur la prise audio faite par le preneur de son, les parties sonores correspondantes, recalant ainsi automatiquement l’enregistrement effectué séparément à l’aide d’une perche ou d’un micro-cravate. Simple comme bonjour et terriblement pratique pour le monteur.
- Envoi du signal à la caméra (via câble)
La façon la plus directe de récupérer l’audio enregistré par le preneur de son est de se connecter à la caméra. Chaque enregistreur possédant une sortie audio séparée de celle du casque, il est facile de tirer un câble pour venir se brancher dans l’une des entrées micro de la caméra. Cette méthode permet ainsi d’avoir un signal audio propre, directement enregistré avec le fichier vidéo, évitant de devoir passer par la phase de synchronisation lors du montage. Toutefois, dès que le nombre de pistes à enregistrer dépasse le nombre d’entrées audio de la caméra, il sera impossible de désolidariser les prises les unes des autres. Ce sera donc un mix général qui sera envoyé à la caméra (souvent en mono), regroupant toutes les sources sonores captées sur le moment. L’intérêt réside ici dans le fait que cela fournira, comme dans le cas précédent, un signal de référence pour que le monteur puisse ensuite synchroniser tout ça au montage à partir des prises bruts du preneur de son. De plus, cela donnera la possibilité au caméraman d’écouter le mix général de la prise de son via la sortie casque de sa caméra. L’avantage étant également d’avoir son retour direct sur la prise et de savoir si un bruit apparaissant en arrière plan est potentiellement dérangeant pour lui (une voiture qui passe, une porte qui claque, etc.) ou s’il considère qu’il est toléré dans la prise.
Cette façon de faire est toutefois assez rare car contraignante. En effet, relier la caméra et l’enregistreur en filaire amène le risque que celui-ci soit tiré de part et d’autre, ce qui pourrait potentiellement détériorer l’un des connecteurs (voire même faire tomber la caméra) si une trop forte tension est exercée dessus. Cette méthode est donc à privilégier uniquement sur un tournage sans mouvement (caméra fixe en studio par exemple) et seulement si vous n’avez pas la possibilité d’envoyer un signal via un émetteur-récepteur sans fil.
Il y a une seconde étape à effectuer pour être certain que le niveau du signal entrant dans la caméra corresponde à ce que vous enregistrez réellement. Chaque enregistreur pro type Sound Devices 702T ou Zoom F8 (les 2 enregistreurs multipistes que je possède) permettent d’émettre un signal audio à 1000Hz. Celui-ci sera joué à -20dBFS ou -12dBFS suivant les modèles. Il suffira ensuite de régler le niveau sonore de façon à ce que celui-ci indique cette même valeur sur le Vu-mètre audio de la caméra. Le réglage pourra s’effectuer sur la sortie de l’enregistreur, sur l’entrée microphone de la caméra ou sur les 2.
Cette vidéo explique comment régler le niveau de sa caméra à partir d’un signal 1000Hz
- Envoi du signal à la caméra (émetteur-récepteur sans fil)
La méthode est exactement similaire à celle citée ci-dessus. La seule différence, c’est qu’au lieu d’envoyer le signal via un câble, celui-ci est délivré par un récepteur sans fil (type Sennheiser AVX ou EW 112P G3 ou G4), évitant ainsi toute contrainte de câble. Bien que cette façon de faire soit beaucoup plus pratique, elle fait apparaître deux problèmes potentiels à ne pas négliger. Premièrement, il est nécessaire de vérifier tout au long du tournage si les batteries des émetteurs et récepteurs fournissent toujours en énergie les appareils. Si les appareils sont éteints et qu’il n’y a plus de signal audio qui rentre dans la caméra et que celle-ci ne possède pas de micro de référence, vous n’aurez tout simplement plus de son. Si aucun clap n’a été effectué, le monteur sera obligé de resynchroniser au visuel, en essayant de faire correspondre les mouvements de bouche de l’intervenant avec l’audio séparé. Une opération qui peut s’avérer horriblement chronophage si le nombre de prises est important. Sans compter que le monteur risque de vous maudire pour tout ce travail en plus, surtout s’il est pressé de rendre son projet.

Un récepteur sans fil Sennheiser AVX connecté à une caméra
- Utilisation d’un Timecode
Il existe une dernière méthode, basée sur le Timecode. En plusieurs années de tournage, je n’ai utilisé cette option que très rarement, mais elle peut s’avérer utile dans plusieurs cas, notamment en mode reportage. En effet, il peut arriver que plusieurs caméras se retrouvent à filmer un évènement avec différents angles de vue différents, et qu’elles filment des moments différents, tout ça, sans être reliées d’une quelconque façon à la sortie audio de l’enregistreur du preneur de son. Toutefois, lors du montage, il pourra être nécessaire de faire correspondre les timings des divers moments captés par les caméras entre eux ainsi qu’avec l’enregistrement audio effectué en parallèle. C’est ici que l’usage du Timecode intervient.
Comment travailler avec le Timecode ? Bien que cette méthode paraisse compliquée au premier abord, elle a été grandement facilité ces dernières années depuis l’apparition d’appareils tels que les Tentacle Sync. Pour commencer, il faut posséder un enregistreur délivrant un Timecode, ce qui est le cas de la plupart des appareils professionnels type Sound Devices 702T (mais pas sa version 702) ou Zoom F8. On reliera alors l’un des boîtiers Tentacle Sync à la sortie Timecode de l’enregistreur via le câble approprié. Il en existe plusieurs sortes, à vous de voir celui qui correspond à votre enregistreur et aux caméras auxquelles vous devrez les connecter. Pour cela, si votre budget le permet, je ne saurais que trop recommander de faire l’acquisition de tous les câbles existants à double exemplaire (car il y aura souvent 2 caméras pour ce type de captation vidéo). Le Timecode délivré par l’enregistreur sera envoyé sur le boîtier Tentacle qui calera automatiquement son horloge interne sur celui fourni par l’enregistreur. Une fois cette opération effectuée on répétera l’opération avec le second boîtier. On pourra aussi relier les 2 boîtiers entre eux en délivrant le Timecode de l’appareil déjà synchronisé avec l’enregistreur, sur celui qui ne l’est pas encore (la manipulation est simple comme bonjour). Et voilà ! Il faudra ensuite accrocher le boîtier à la caméra via du scotch ou un velcro (présent d’office sur le boitier Tentacle Sync), le brancher sur son entrée Timecode et le tour est joué. Pour les caméras ne possédant pas d’entrée Timecode comme c’est le cas sur des appareils type Reflex ou DSLR, il existe la possibilité de faire transiter le Timecode via un canal audio à travers un connecteur minijack ou XLR. Ce sera ensuite au tour du logiciel de montage de prendre le relai en synchronisant les prises audio et vidéo selon le Timecode de chacun.

Les boîtiers Timecode de chez Tentacle Sync


{kind=link}
{kind=link}
{kind=link}